消息端到端的一致性与可靠性¶
约 4688 个字 3 张图片 预计阅读时间 16 分钟
背景介绍¶
-
可靠性: 消息一旦显示发送成功就必定送达到对端
-
一致性:任意时刻消息保证与发送端顺序一致。
消息可靠与一致对于IM来说,就是指: 可达有序,不重不漏。
设计IM必须具有端对端的设计思维,底层对可靠性的保证仅能保证底层的可靠,而不能保证上层的可靠, 底层的可靠仅是减小了发生故障的概率: 底层可靠不等于上层可靠,同理: 底层一致不等于上层一致
消息的端到端可靠性 = 上行消息可靠 + 服务端业务可靠 + 下行消息可靠
消息的端到端一致性 = 上行消息一致 + 服务端业务一致 + 下行消息一致
为论述方便,下文中提到的_消息可用指的是IM消息可用性_, 包含消息可靠性和一致性两个方面
TCP其实自带超时重传机制,保证了消息可靠性的传输,那么为什么我们还要再去讨论和实现 消息可用 呢?
TCP究竟帮助我们做到哪一步?
-
客户端A 发送 msg1和msg2两个消息给到服务端。
-
msg1和msg2在一个tcp链接上到达服务端。
理论上来说,msg1 和 msg2 是遵循顺序从客户端 A 发送到服务端的,似乎消息是一定收到的,但是这其实是一个端到端可靠性的问题,TCP 作为传输层协议,只能说消息可靠到达了传输层,但是不能说消息可靠到达了业务层。
问题
-
在传递给业务层时服务端进程崩溃,但客户端A认为已经送达,服务端业务层无感知, 自然无法发送到客户端 B,因此消息丢失。
-
msg1和msg2到达应用层, 解析后交由两个线程处理, 可能msg2 消息体小一些,msg1 消息体大一些,导致了m2 先解析完毕,落表后先发送给客户端 B, 造成消息乱序。
-
msg1消息存储失败,msg2消息存储成功先发送给了客户端B,造成丢失且乱序。
Tips
洞见: TCP/UDP是双方通信 (本质上是 C/S 模式),而IM本质上是三方通信。
技术挑战在哪里?
-
三方通信,网络层面无法保证消息必达。
-
没有全局时钟,确定唯一顺序,且是符合因果顺序的。
-
多客户端发送消息/多服务端接收消息/多线程多协程处理消息,顺序难以确定。
方案选型¶
及时性,可达性,幂等性,时序性
1. 消息及时: 服务端实时接收消息并实时在线发送。¶
及时性强调客户端双方进行端到端通信的过程中,要保证能够在 200ms 以内完成,也就是说,一旦一个功能超过 200ms,用户就会感知到延迟现象,但是对于一些大规模的场景,比如说_网络的高峰期,或者数据中心的负载比较高_,那么这个时候可以允许 p99 达到 1 秒,但是如果超过 1 秒,用户就会觉得收发消息非常卡顿。
2. 消息可达: 超时重试,ACK确认。¶
类似 TCP 协议通过 超时重试 和 ACK 确认 机制来保证消息的可靠传输,同样可以采取类似的机制来保证 消息可达性。
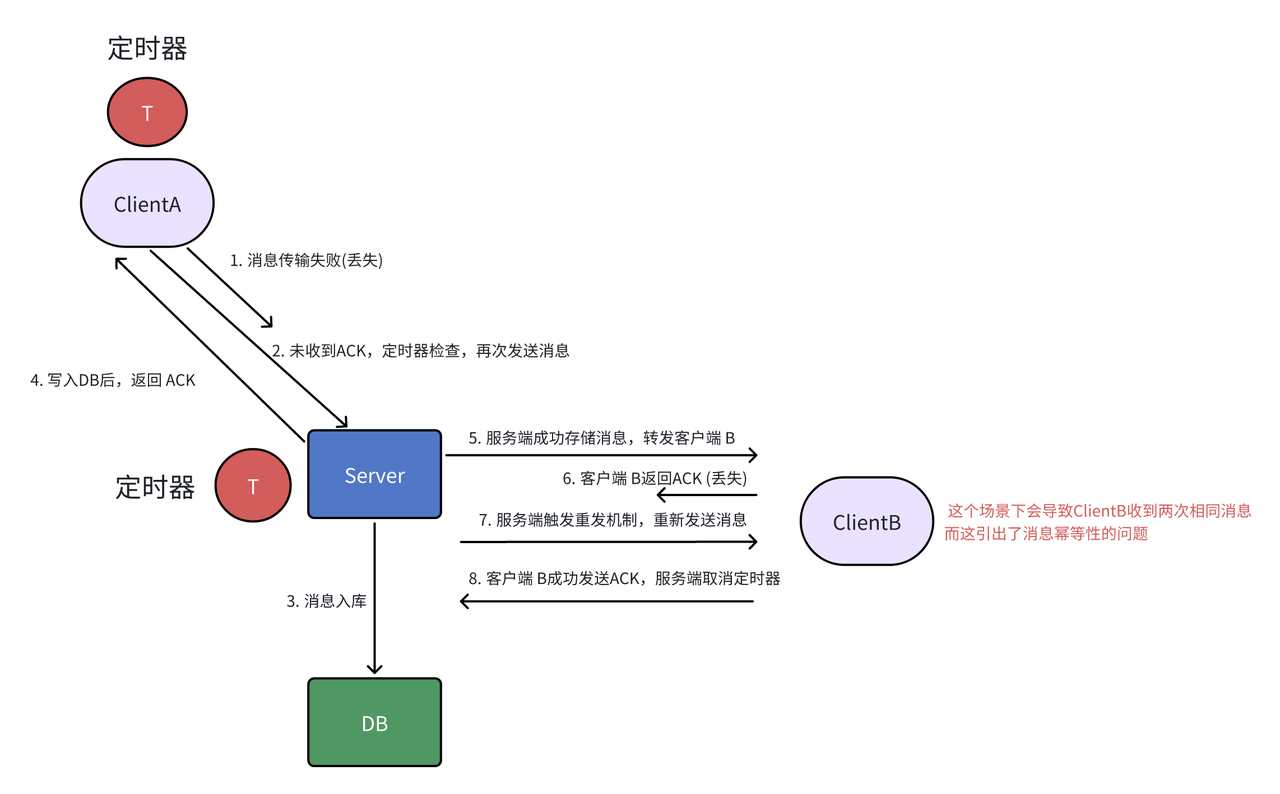
消息传递流程
-
客户端 A 到服务端:
-
客户端 A 发送消息到服务端。
-
服务端将消息 先落库(存入数据库)。这一步保证了即便服务端崩溃,消息也不会丢失。
-
一旦消息成功写入数据库,服务端会返回 ACK 确认 给客户端 A,表示消息已成功接收,无需重发。
-
-
消息传输失败的重试机制:
-
如果客户端 A 没有收到 ACK 确认,即说明消息未成功传输。此时,客户端 A 会启动 定时器,定期检查是否超时。
-
如果超时,客户端 A 会重新发送消息。
-
消息再次到达服务端后,服务端会再次写入数据库并返回 ACK。
-
-
消息到达客户端 B 的流程:
-
服务端在成功存储消息后,开始将消息发送给客户端 B。
-
客户端 B 在接收消息时也会执行 ACK 确认。
-
如果客户端 B 发送的 ACK 丢失,则会触发服务端的 重发机制,重新发送消息,直到接收到 ACK 确认。
-
-
丢失 ACK 的情况:
-
如果客户端 B 收到消息后,ACK 确认丢失,客户端 B 会重新发送 ACK。
-
服务端收到新的 ACK 后,会 取消定时器,停止重发消息。
-
5. 消息幂等: 分配seqID,服务端存储seqID。¶
6. 消息有序: seqID可比较,接收端能按发送端的顺序对消息排序。¶
消息幂等与消息有序的解决思路即为消息分配 ID,将在下文中详细讨论。
这里简要阐述 消息ID 的设计逻辑
| Text Only | |
|---|---|
如果说仅仅使用一个 messageID 去实现各种功能,那么这个设计的复杂度是非常高的。
为了降低设计的复杂度,消息ID 可以按照消息的不同用途拆分成多种 ID,虽然在存储空间上有一定的浪费,但是ID 设计方案的复杂度可以降低很多。
-
clientID:clientID是一个链接级别的 ID,当一个客户端与服务端建立链接后clientId被正式初始化为 0,强调的是客户端发送方消息的逻辑顺序,这个顺序由用户自己触发和维护,完全符合于用户,同时 id 大小与用户发送消息的先后有关。但是在群聊场景中,每一个用户的clientID是一个偏序,只能保证自身的有序性(局部有序),而不是全局有序。所以在服务端中,不能用clientID做消息汇总和消息转发。因此我们需要一个全局有序的 ID,即seqID。( 需要补充的是,为什么可以这样设计?原因在于 TCP 在 4 次挥手完成后,会有一个 2MSL 的 TIME_WAIT,保证上一个 TCP 链接的消息不会影响到下一个 TCP 链接,所以可以这么说,clientID的生命周期是从客户端发送给服务端,服务端接收为止,这个 clientID 就没有意义了 ) -
sessionID:sessionID即为会话 ID,用于标识客户端的会话。原因是在用户的聊天界面,可能存在多个会话,而消息的时间线排序,是对于每一个会话来说的,同时sessionID也起到帮助服务端找到消息所在的会话的作用。所以,客户端向服务端发送消息时要传递clientID和sessionID。 -
seqID:seqID是一个会话级别的 ID,本质上起到两个作用,一是保证唯一性从而实现幂等,二是保证有序性 (将客户端消息的顺序性传递到服务端)。seqID由服务端维护并分发,是每个会话所特有的,具体表现为,在 Redis 中以msg:{sessionID}:seqID - int64格式存储,其中sessionID为可变量,value通过lua脚本incrby。如果seqID作为一个全局变量,可能会存在单点问题,Redis 的上限为十万 QPS,而消息转发可能远大于 10 万 QPS 的量级,但是引入sessionID则可以显著降低问题发生的可能性,一种方案是根据sessionID做 Redis 集群分片,实现水平扩展。 -
msgID:msgID是一个应用级别的 ID,作用是保证消息的全局唯一性。生成方案可以是雪花算法,也可以通过seqID + sessionID通过某种算法变换得到。
对 seqID 做一些补充。
seqID 的特点是万有一失的严格递增,处于严格递增和趋势递增的中间态。在一个较长的时间范围内,保证严格递增是非常困难的。通过 redis 举例阐述,redis 存在主从节点,并通过 pull 模式进行主从同步,此时从节点对主节点发起 pull,得到的 seqID 为 1000,在这个瞬间 master 节点异步地分配了一个 seqID 并自增到 1001 并且发生了单点故障,那么就会发生主从切换,这样的结果是出现了 2 次值为 1000 的 seqID 分配到了不同的消息上,这种现象被称为回退。
解决这个问题的方法是,可以使用 lua 脚本操控 redis,并通过 runid 判断主从节点
-
第一次查询时,首先
,如果获取到的 ,如果获取到的 到的runid和之前的runid是一致的,则直接incrby并返回seqID` -
如果发生了主从切换,那么获取到的
runid是不一致的,为了避免回退,可以给当前的seqID加上一个偏移值,可以是当前时间戳等幅度较大的数值,用这段跳变防止发生回退,且能保证唯一性,而因为 redis 的主从切换的频率并不高,所以在 99% 的时间内都是严格递增的,所以称其为万有一失的严格递增
但是上述解决方案又引出了另一个问题:万有一失的严格递增能够保证不回退,但是不能保证不跳变(称其为消息漏洞),那么客户端应该如何识别这个跳变是主从切换引起的还是消息丢失引起的?
解决方案也较为简单,当客户端发现出现了消息漏洞,即消息 ID 不连续的情况,那么就向服务端主动拉取一个分页的历史消息请求(称其为消息补洞),通过这种推拉结合的方式,进行对比后,就可以判断是发生了主从切换还是消息丢失了。
上行消息¶
客户端A将消息发送给服务端,这一阶段要保证消息从客户端到服务端的可用性。
| 方案 | 收益 | 代价 |
| clientID 严格递增 1. 客户端A创建会话与服务端建立长连接 2. 在发送消息msg1时分配一个clientID 此值在会话内严格递增 3. 连接建立时 clientID 初始为0。 4. 服务端将上一次收到消息的clientID缓存为preClientID,当且仅当 clientID == preClientID + 1时接收此消息(保证幂等)5. 仅当服务端接收到消息后才回复客户端A,ACK消息 6. 仅当客户端A收到服务端对消息ACK的回复,才禁止重发(可设置最多三次) |
1. 任意时刻仅存储一个消息ID 2. 保证严格的有序性 3. 实现简单,可用 4. 长连接通信延迟低 5. 以发送方顺序为标准(权衡) |
1. 弱网情况下,消息丢包严重时将造成大规模消息重发,导致网络瘫痪影响消息及时性。 2. 无法保证群聊中的消息因果顺序 |
| 弱网问题,可以通过优化传输层协议(比如协议升级为Quic)来优化,长连接不适合在弱网环境工作,丢包和断线 属于传输层问题。 | ||
| clientID 链表 1. 客户端A使用本地时间戳作为clientID,并在每次发送消息的时候携带上个消息的clientID。 2. 服务端存储上一个消息的clientID记作为preClientID,只有preClientID 和 当前消息的preClientID对比,匹配上则说明消息未丢失,否则拒绝。 |
1. 协议的消息带宽 | |
| clientID list 1. 服务端针对每个连接存储多个clientID,形成clientID list 2. 使用此 client List作为滑动窗口,来保证消息幂等 |
1. 减少弱网重传时的消息风暴问题 | 1. 实现更加复杂 2. 网关层需要更多内存维护连接状态 3. 由于传输层使用tcp,已经对弱网有一定的优化,应用层也维护滑动窗口收益不大 |
消息转发¶
分配seqID,异步存储消息,处理业务逻辑,将消息转发给客户端B。
为什么要分配seqID?
IM场景中聊天会话至少有两个客户端参与(单聊/群聊),因此任何一个客户端分配的clientID都不能作为整个会话内的消息ID,否则会产生顺序冲突,因此clientID仅是保证消息按客户端A发送的顺序到达服务端,服务端需要在整个会话范围内分配一个全局递增的ID。
Tips
洞见: 事实上仅需要保证同一个客户发送消息的先后顺序即可。
消息转发的可用性如何保证?
| 方案 | 收益 | 代价 |
| 如果服务端在分配seqID前此请求失败或进程崩溃怎么办? 服务端在分配seqID之后再回复ACK消息。 |
保证了分配seqID消息的可用性 | 1. ack回复变慢,收发消息变慢 2. 如果消息存储失败消息将丢失 3. seqID 分配成为性能瓶颈 |
| 如果服务端在存储消息,业务处理,接入层路由时失败怎么办? 1. 消息存储后再回复ACK,如果ACK失败则客户端重试时再次幂等地回复ACK。 2. 一旦消息存储,如果服务崩溃导致长连接断开,客户端重新建立连接时可以发送一个pull信令,拉取历史消息进行消息补洞,以此保证消息可用性。 3. 如果消息存储后,仅是业务层失败,接入层长连接无感知,业务层需要做异常捕获,并追加pull信令请求给到客户端B,主动触发其拉取历史消息。 |
1. 保证了业务处理全流程的可用性 2. 在出现异常情况时,可毫秒级触发接收端,保证消息及时性 |
1. 上行消息的p95延迟将增加 2. 整体通信复杂度增高 3. 应对弱网环境需要协议升降级机制 |
| 可以将消息交给MQ异步存储,MQ来保证消息不丢失。 | 异步写入,优化了p95延迟 | |
| seqID无需全局有序,仅保证在会话内有序即可 | 解决了seqID分配的单点瓶颈 |
下行消息¶
服务端将消息发送给客户端B,其协议设计依赖于seqID的生成方式。
| 方案 | 收益 | 代价 |
| 客户端定期轮询发起pull请求拿到新消息 | 实现简单,保证可用性 | 1. 客户端耗电高(用户体验差) 2. 消息时延高,不满足及时性 |
| 依赖seqID的严格递增 1. 用redis incrby 生成seqID, key是sessionID/connID。 2. 按消息到达服务端的顺序分配seqID,使其具有会话范围内的全局序。 3. 服务端保证seqID严格递增的前提下将消息发送给客户端B,客户端B也是按 preSeqID == seqID+1的方式来做到幂等4. 服务端需等待客户端B的ACK消息,否则超时后需要重传 |
1. 实现简单,可以快速上线 2. 最大程度的保证严格递增 |
1. 弱网重传问题 2. Redis 存在单点问题,难以保证严格递增 3. 需要维护超时重传消息队列以及定时器 4. 不能解决客户端B不在线时消息的传递 |
| 应对redis的单点故障,seqID的趋势递增 1. 使用lua脚本,存储maxSeqID以及当前的node的runID。 2. lua脚本每次获取ID时,都会检查当前node的runID和存储的runID是否一致 3. 发现不一致时,说明发生了主从切换,然后对maxSeqID进行一次跳变保证递增,避免从节点由于同步数据不及时分配了一个曾经分配过的ID出去 4. 客户端B在发现消息不连续时不是直接拒绝,而是发送pull信令进行增补 5. 如果拉取不到新消息,则说明是seqID的跳变导致,不再进一步处理 6. 如果客户端B不在线,查询用户状态后仅存储不推送即可 |
1. 尽最大可能保证连续性 2. 任意时刻保证单调和递增性 3. 由于使用会话级别的seqID,则不需要全局分布式ID生成,redis可以使用cluster模式进行水平扩展。 4. 识别了用户是否在线的状态,减少了网络带宽消耗 |
1. 协议交互变得更加复杂,实现难度上升。 2. 可评估用户规模进行决策是否支持如此级别的可用性 3. 群聊场景,将造成消息风暴 |
| 推拉结合+服务端打包整流 | 解决消息风暴问题 | 实现更加复杂 |
| SeqID 链表 1. 客户端B在本地存储最后接收到的seqID的值记作maxSeqID 2. 服务端发送消息时,携带上一条消息的seqID记作preSeqID和当前seqID 3. 客户端B接收消息时通过对比maxSeqID == preSeqID 则接收否则拒绝 4. 服务端在设计消息存储时,要存储上一条消息的seqID,形成逻辑链表 5. 客户端发现preSeqID不一致,则退化为pull请求去拉缺失的消息 |
1. 屏蔽了对seqID 趋势递增的依赖 | 1. 收益不大,且在消息存储时要多一个preSeqID |
最终方案¶
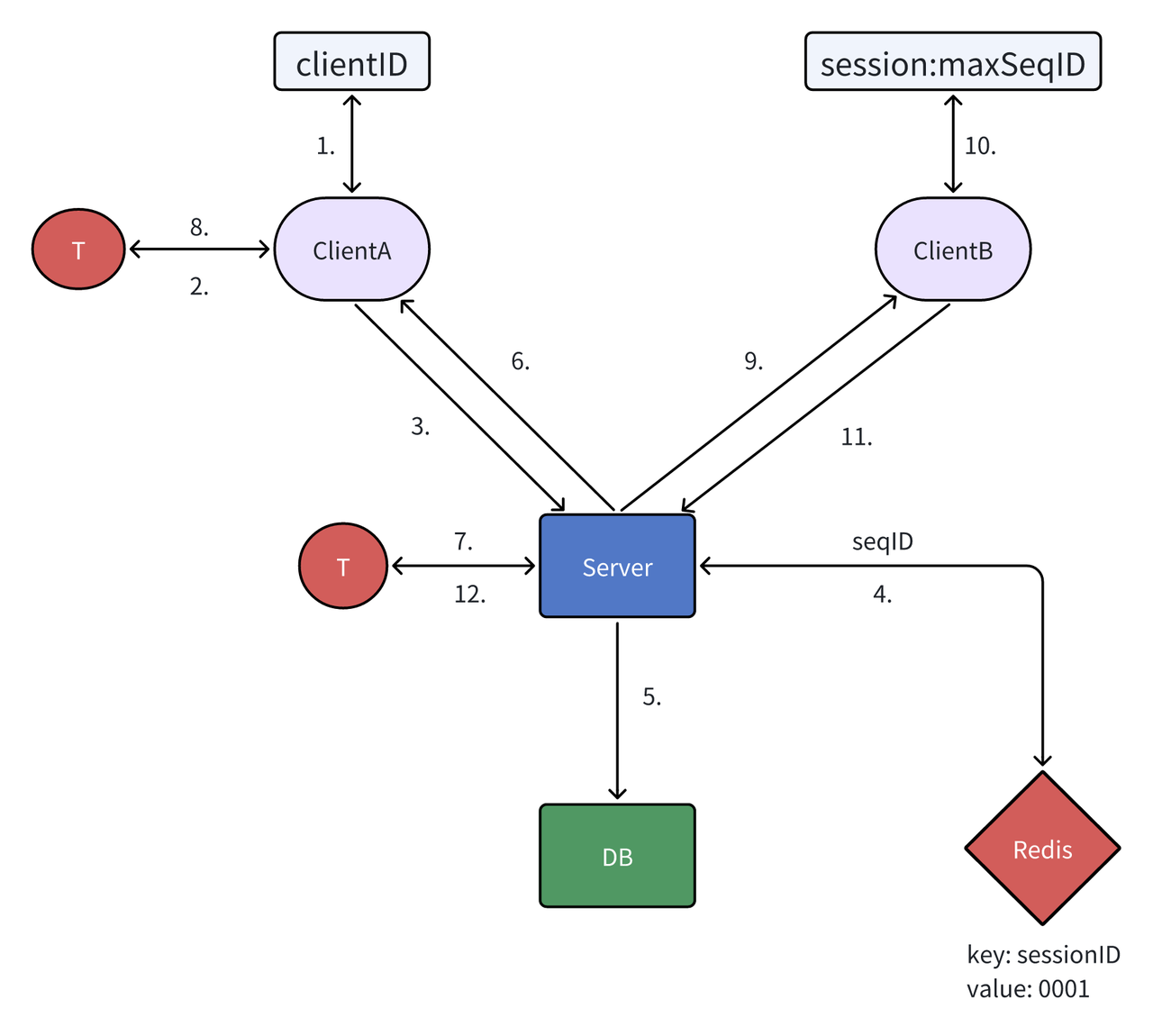
-
客户端A创建连接后,分配一个clientID,从0开始即可,发送一个消息时获得clientID并自增。
-
启动一个消息计时器,等待ack消息的回复,或者超时后触发重传。
-
基于tcp连接将msg1发送给服务端。
-
服务端请求redis使用sessionID进行分片,incryBy获得seqID。
-
异步写入MQ,保证消息可靠存储。
-
立即回复客户端A ack消息,告诉他消息已经可靠送达。
-
启动一个下行消息定时器,等等客户端B的ack消息,或者超时后触发重传。
-
客户端A收到ack消息后,取消定时器。
-
服务端发起下行消息请求,将msg1发送给客户端B。
-
客户端B根据当前session的maxSeqID+1 是否等于当前消息的seqID来决定是否接收。
-
客户端B回复服务端消息已经确认或者拒绝。
-
服务端根据客户端B回复决定是进行消息补洞还是关闭定时器。