循环依赖¶
约 908 个字 17 行代码 4 张图片 预计阅读时间 3 分钟
什么是循环依赖¶
首先了解一下 Bean 的初始化流程,单例 Bean 从创建到完成,主要经历了三步。

循环依赖可以用一个例子来理解,在 Spring 中,a 依赖 b,b 依赖a,形成了一个闭环,在这种情况下,初始化任意一个 Bean,都会导致最终又依赖回自己,导致初始化失败。
解决循环依赖流程¶
spring 用了三级缓存解决循环依赖。
- 一级缓存:
Map<String, Object> singletonObjects是成品对象单例池,用于保存实例化、属性赋值 (注入)、初始化完成的 bean 实例 - 二级缓存:
Map<String, Object> earlySingletonObjects存储早期曝光对象,用于保存实例化完成的 bean 实例 - 三级缓存:
Map<String, ObjectFactory<?>> singletonFactories是早期曝光对象工厂,保存 bean 创建工厂(ObjectFactory)
一级缓存作用¶
在获取对象的时候,会调用 getSingleton(beanName) 方法,从一级缓存获取 Bean,如果不存在,就会调用重载方法 getSingleton(beanName, 创建方法) 创建 Bean 后,将它设置回一级缓存。
三级缓存作用¶
在 createBean 方法中,调用具体的 doCreateBean 方法
主要做了如下几件事
- 实例化对象
- 将对象的创建工厂保存在三级缓存中
- 属性赋值
- 初始化处理 (前置,初始化方法,后置)
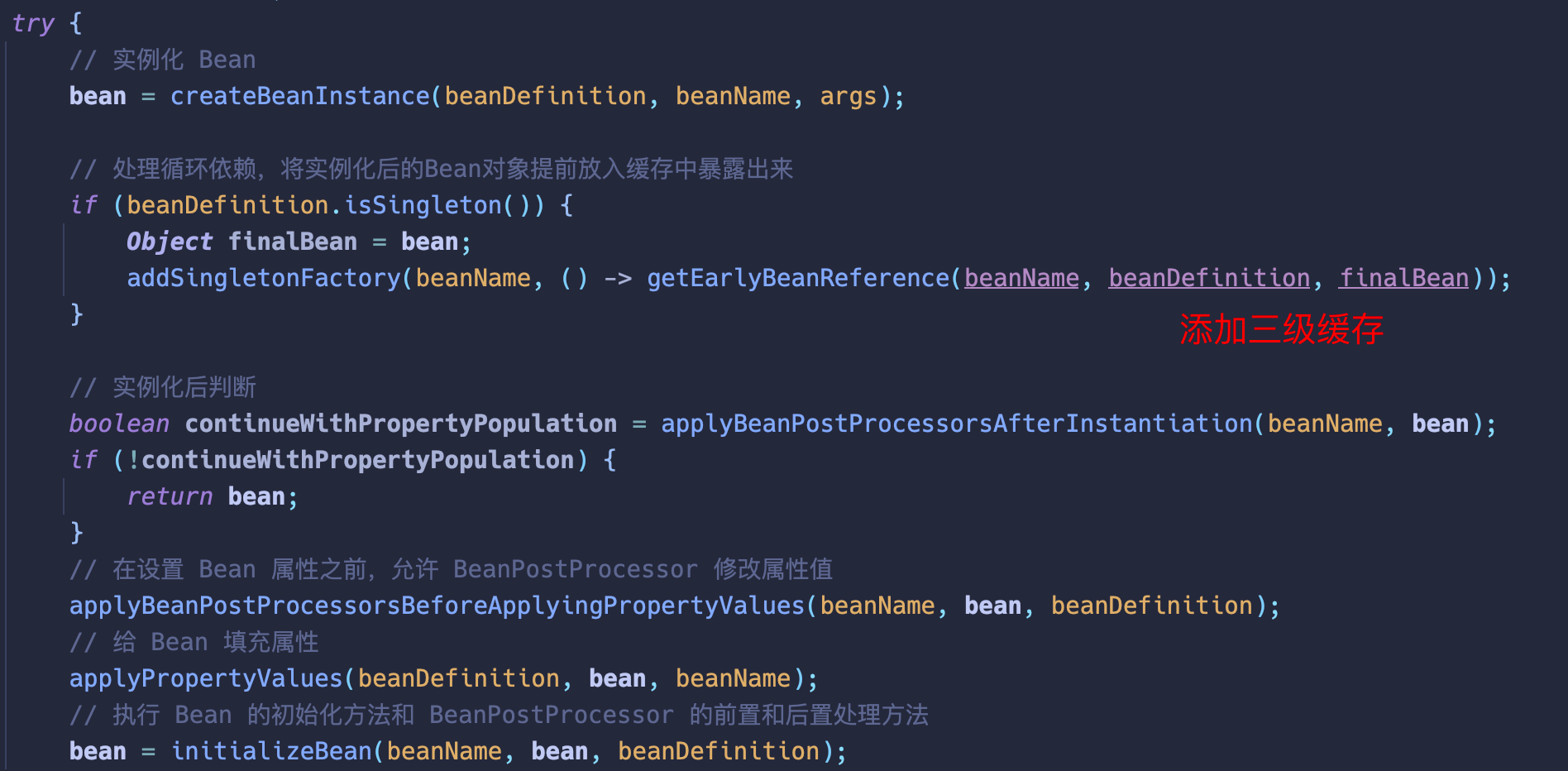
对象工厂做了什么
本质上的作用是暴露一个早期对象。把所有实现了 InstantiationAwareBeanPostProcessor (Spring 源码中为 SmartInstantiationAwareBeanPostProcessor ) 的后置处理器提前运行。AOP 在这里提前执行。
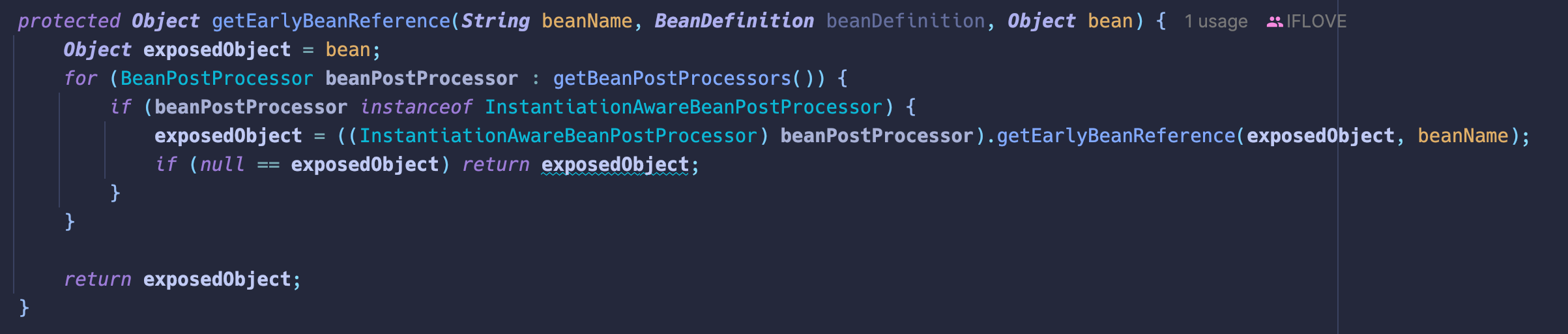
可以这么说, SmartInstantiationAwareBeanPostProcessor 就是为了解决循环依赖而生的。
二级缓存作用¶
在属性赋值阶段,如果出现了循环依赖,解决循环依赖的流程如下:
-
A 实例化成功
-
A 把自己的 ObjectFactory 保存在三级缓存
-
A 属性赋值依赖 B
-
B 实例化成功
-
B 把自己的 ObjectFactory 保存在三级缓存中
-
B 属性复制依赖 A,这时候 B 调用的是复用的
getSingleton(beanName)方法,底层会先去一二级缓存中找 A,如果都找不到,会找到三级缓存,然后调用对象工厂的获取对象方法,获取代理后或者没有代理的对象(这个取决于 wrapIfNecessary 逻辑),最后把得到的对象放到二级缓存中,删除三级缓存。 -
之后如果 C 也依赖了 A,那么也能在二级缓存中找到这个代理对象。一旦 A 初始化完毕,会将自己放入一级缓存中,同时删除二级缓存。
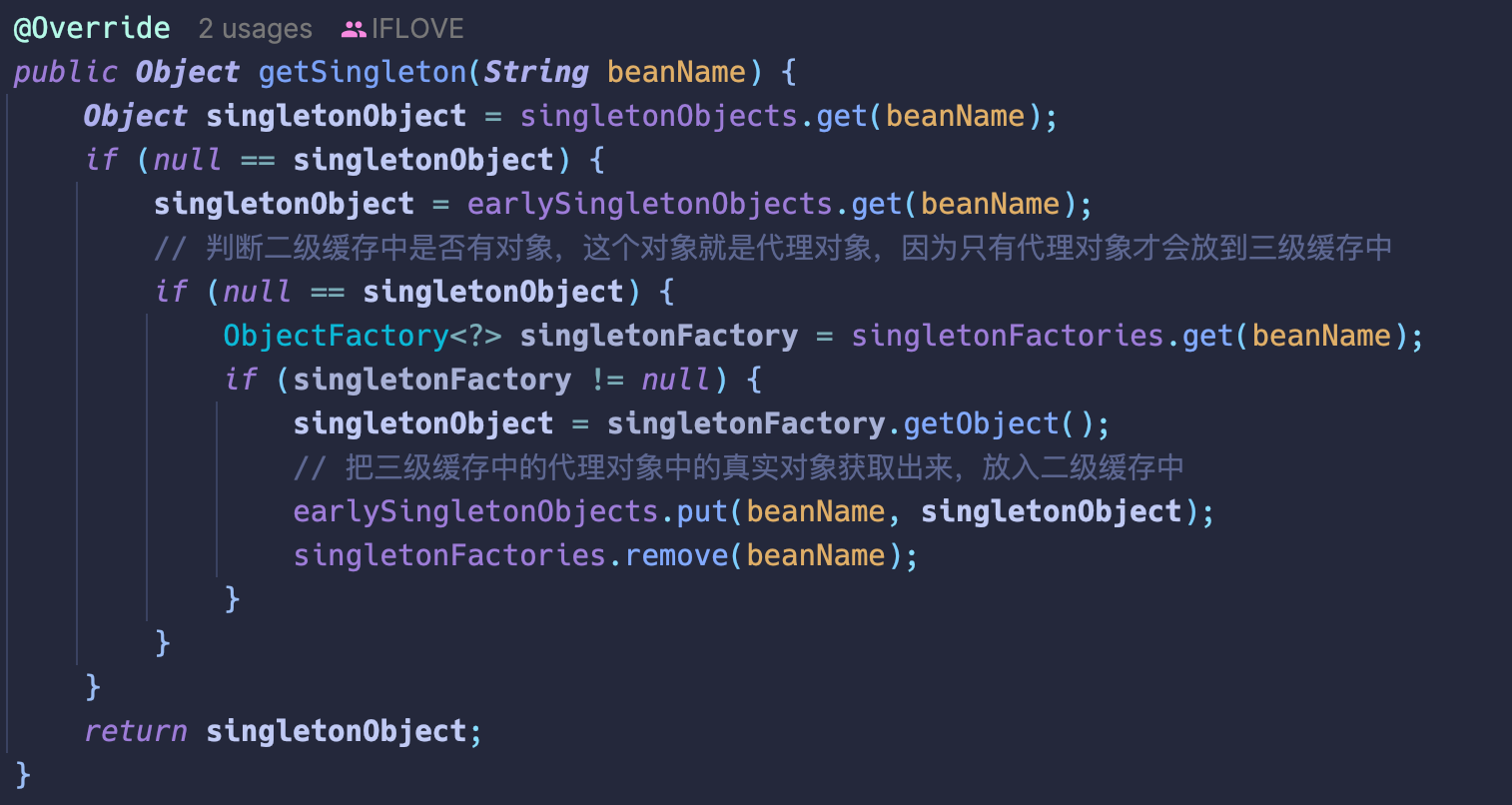
只用一二级缓存,能否解决循环依赖¶
理论上,只用一二级缓存就能解决循环依赖问题了,我们可以抛弃三级缓存,我们知道三级缓存的 value 本质上是一个对象工厂,那么是不是可以在对象实例化的时候,都去执行一遍 ObjectFactory 的创建对象方法,将代理对象存储在二级缓存里即可。
三级缓存其实是和 spring 规范挂钩的。
因为 aop 的实现是靠实现了 SmartInstantiationAwareBeanPostProcessor 接口的 AnnotationAwareAspectJAutoProxyCreator 在 bean 的后置处理器生效的,也就是说,是在 bean 的生命周期的最后一步生效的。如果每个对象刚刚实例化,就执行了后置处理器,那和 spring 的生命周期是相悖的。为此,spring 采用了三级缓存机制,只有在循环依赖的时候,才会打破生命周期,提前获取代理对象,并且只是最小程度的打破。